語音處理(voice processing)的第一步就是語音辨識(voice recognition)。語音辨識就是把接收的所有聲音裡,過濾出真正的使用者聲音。這個過程是在音訊前端(Audio Front End, AFE)的階段完成。通常用到語音辨識的產品,也同時會有喇叭播放音樂或是語音,亦即會用到雙工(duplex)的系統,故我們需要去除回聲(Acoustic Echo Cancelling:AEC)把喇叭的聲音先去掉。去掉之後,我們再來分析殘留的聲音訊號。
通常語音辨識都會有麥克風陣列,所以可以判定聲源位置,判定完聲源位置之後可以用波束成形(beamforming)。這個波束成形通常需要演算法2~3毫秒的資料來判斷,以準確判斷使用者的位置。波束成形對對中高頻聲源有辦法定位、強化,但是對低頻的效果並不佳。解決方法之一是把兩個麥克風單體之間的距離拉大,這樣會增強低頻效果,但是缺點就是高頻會有問題:因為當麥克風之間的距離變大,超過一個波長時,距離內就會產生不只一個週期的聲波,這樣會產生假象頻率(aliasing frequency)。另一個解決方法是,讓麥克風們之間的距離不一(un-uniform)
接著,即使瞄準這個聲源了,但免不了還是會收到這個方向的噪音,所以最後會把這個噪音去掉。這個過程中,如何定義何謂噪音,何謂目標音源,就是仰賴各加軟體廠商的能力了。例如,如何能收進使用者的語音指令,但是又不收進電視機的對白,至關重要。更進一步,有種使用者身分辨識(speaker ID verification)的軟體,這個適用於個人化、具有使用隱私的裝置,例如穿戴式裝置或者手機。這些裝置必須只聽命於他主人的語音指令,不能被其他路人甲乙喚醒,這就涉及到聲紋(acoustic fingerprint)辨識的部分。
語音辨識一開始時,使用者都會先叫出喚醒字詞(wake word),例如對Apple產品就是”Hi Siri”。系統能否辨認出這個喚醒字詞,就衍伸出所謂的型一錯誤(Type I error)跟型二錯誤(Type II error)。較常用的良率指標是拒絕率(False Rejection Rate:FRR),也就是使用者講了很多次喚醒詞,但其中卻有幾次沒有成功換醒。如果系統聽了10次,有1次沒有成功反映,那拒絕率為10%。
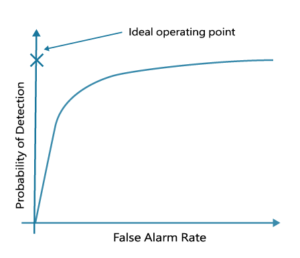
承上思路,我們會希望提高辨識的靈敏度。但靈敏度太高也會有困擾,也就是會產生假警報(false alarm)。如下圖所述,縱軸為成功判斷出喚醒詞的機率,橫軸為假警報的機率。理想中是希望目標點在縱軸,值越高越好,也就是接收度高,但是不會把其他訊號誤判成關鍵喚醒。但現實生活中總有取捨,如果靈敏度太高,雖然接收率較高,但誤判率也會較高。
昊宬目前所販售的語音IC是燒錄聲音的IC部分。