The first step in voice processing is voice recognition. Voice recognition involves filtering out the user’s actual voice from all the sounds received. This process is completed at the Audio Front End (AFE) stage. Products that use voice recognition typically also have speakers playing music or speech, meaning they require a duplex system. Therefore, we need to remove the speaker’s sound using Acoustic Echo Cancelling (AEC) first. After removing it, we then analyze the remaining sound signals.
Voice recognition typically uses a microphone array, which allows for determining the source’s location. After determining the location, beamforming can be applied. This beamforming typically requires 2–3 milliseconds of data for the algorithm to accurately determine the user’s position. Beamforming works well for localizing and enhancing mid-to-high frequency sources, but its effectiveness for low frequencies is limited. One solution is to increase the distance between two microphones, which would enhance low-frequency effects. However, the downside is that high frequencies may be affected, because when the distance between microphones exceeds one wavelength, multiple cycles of sound waves are generated within the distance, leading to aliasing frequency. Another solution is to make the distance between microphones non-uniform.
Next, even after targeting the source, there will still be noise received from that direction, so the noise will eventually be removed. During this process, how to define what constitutes noise and what constitutes the target sound source relies on the capabilities of various software manufacturers. For example, how to capture the user’s voice command while filtering out the dialogue from a TV is crucial. Further, there is software for user identification (speaker ID verification), which is used in personalized, privacy-sensitive devices, such as wearables or smartphones. These devices must only respond to their owner’s voice commands and should not be triggered by other people, which involves acoustic fingerprint recognition.
At the start of voice recognition, the user will first say a wake word, such as “Hi Siri” for Apple products. Whether the system can recognize this wake word leads to what is known as Type I error and Type II error. A commonly used yield indicator is the False Rejection Rate (FRR), which measures how many times the user says the wake word, but it does not successfully activate the system. If the system hears the wake word 10 times and fails to respond once, the rejection rate is 10%.
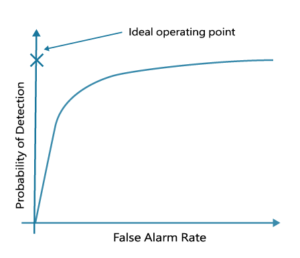 Following the same logic, we aim to improve the recognition sensitivity. However, a sensitivity that is too high can lead to issues such as false alarms. As shown in the figure, the vertical axis represents the probability of successfully detecting the wake word, while the horizontal axis represents the probability of false alarms. Ideally, the target point should be at the vertical axis with the higher value being better, meaning high reception, but without misjudging other signals as the wake word. In reality, there is always a trade-off: if the sensitivity is too high, while the reception rate is higher, the false alarm rate will also increase.
Following the same logic, we aim to improve the recognition sensitivity. However, a sensitivity that is too high can lead to issues such as false alarms. As shown in the figure, the vertical axis represents the probability of successfully detecting the wake word, while the horizontal axis represents the probability of false alarms. Ideally, the target point should be at the vertical axis with the higher value being better, meaning high reception, but without misjudging other signals as the wake word. In reality, there is always a trade-off: if the sensitivity is too high, while the reception rate is higher, the false alarm rate will also increase.
The voice ICs currently sold by Haosen are part of the sound-recording IC segment.